
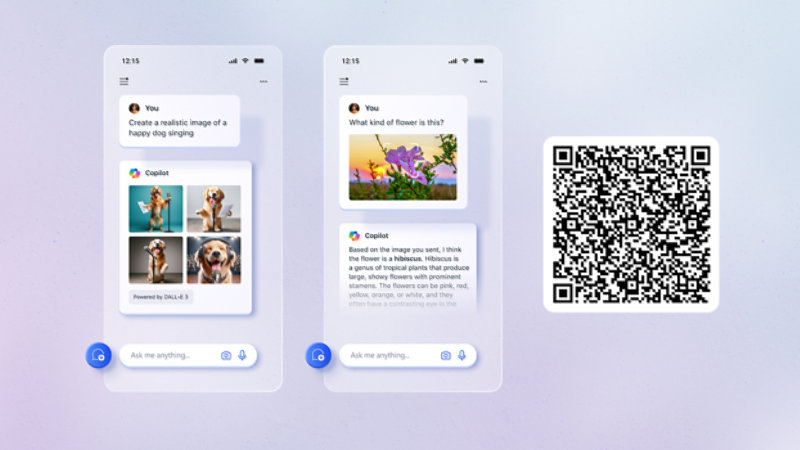
Unlock your potential with Microsoft Copilot
Get things done faster and unleash your creativity with the power of AI anywhere you go.
Visual Studio 2003 Retired Technical documentation
The content you requested has already been retired. It is available to download on this page.
Important! Selecting a language below will dynamically change the complete page content to that language.
Version:
2003
Date Published:
9/21/2017
File Name:
VS2003_CPP_en-us.pdf
VS2003_General_en-us.pdf
VS2003_JScript_en-us.pdf
VS2003_JSharp_en-us.pdf
VS2003_VB_en-us.pdf
File Size:
94.4 MB
51.9 MB
3.2 MB
10.5 MB
23.9 MB
Visual Studio .NET is the tool for rapidly building enterprise-scale ASP.NET Web applications and high performance desktop applications. Visual Studio includes component-based development tools, such as Visual C#, Visual J#, Visual Basic, and Visual C++, as well as a number of additional technologies to simplify team-based design, development, and deployment of your solutions.Supported Operating Systems
Windows 2000 Service Pack 2, Windows ME, Windows Server 2003, Windows XP Home Edition , Windows XP Professional Edition
A PDF viewer- The download is a pdf file. To start the download, click Download.
- If the File Download dialog box appears, do one of the following:
- To start the download immediately, click Open.
- To copy the download to your computer to view at a later time, click Save.
Follow Microsoft